GPT Image 2
GPT Image 2 核心应用场景
整合后的场景概览,将重复受众合并为更通用的生产型工作流。
营销与广告团队
可用于生成广告创意、社媒素材、信息图活动图和品牌邮件视觉,文字渲染稳定、版式一致性更好。
UI/UX 设计师与产品经理
可快速原型化应用界面、网站布局和产品概念,并更好地控制层级、排版与构图。
电商商品视觉
可规模化生成商品图与详情页视觉,标签、包装文字、条形码可读性更好,品牌风格更一致。
内容创作者与出版团队
可生成可视化报告、编辑插图、封面和博客配图,注释清晰、视觉风格统一。
教育、科研与技术传播
可构建科研图解、历史重建图和技术插图,结构表达和标注质量更清晰。
游戏与互动媒体团队
在构思与原型阶段加速角色、环境和界面资产的概念开发。
GPT Image 2 的核心功能
可直接投产的文字渲染: 能够稳定渲染密集、多语言、排版要求高的画面,标点、大小写与位置更可靠。
像素级精细编辑: 可在局部编辑时保持原有光照、材质纹理与场景构图不变。
世界知识驱动的真实感: 在历史、科学和信息密集型图像中提升结构合理性。
生产级 4K 输出: 支持最高 4096 x 4096 高分辨率与宽画幅构图,满足商业交付。
更强指令遵循能力: 可更稳定处理多主体复杂提示词,并精确控制位置、属性与层级。
先进真实感表现: 以质量优先的架构提升写实效果,强化光照与材质还原。
品牌一致的商品摄影: 商品标签、Logo 与包装文字可读性更稳定,并保持品牌一致性。
像素级 UI 与版式复现: 可高保真复现复杂界面结构与信息密集型布局。
可直接投产的文字渲染
结合两版能力后,该特性主要面向信息图、标识、UI 原型和包装设计等场景,长文本与小字号在不手工修正的情况下也能保持可读。
示例 1
Prompt
创建一张高质量、写实风格的现代咖啡店门头图像。门上方主要发光霓虹招牌需清晰写出“Morning Brew”,使用优雅手写体。下方较小的黑板招牌需清晰可读地写出“Espresso & Pastries”,字迹整洁。整体灯光温暖、有吸引力,场景中的文字排版保持一致。
结果
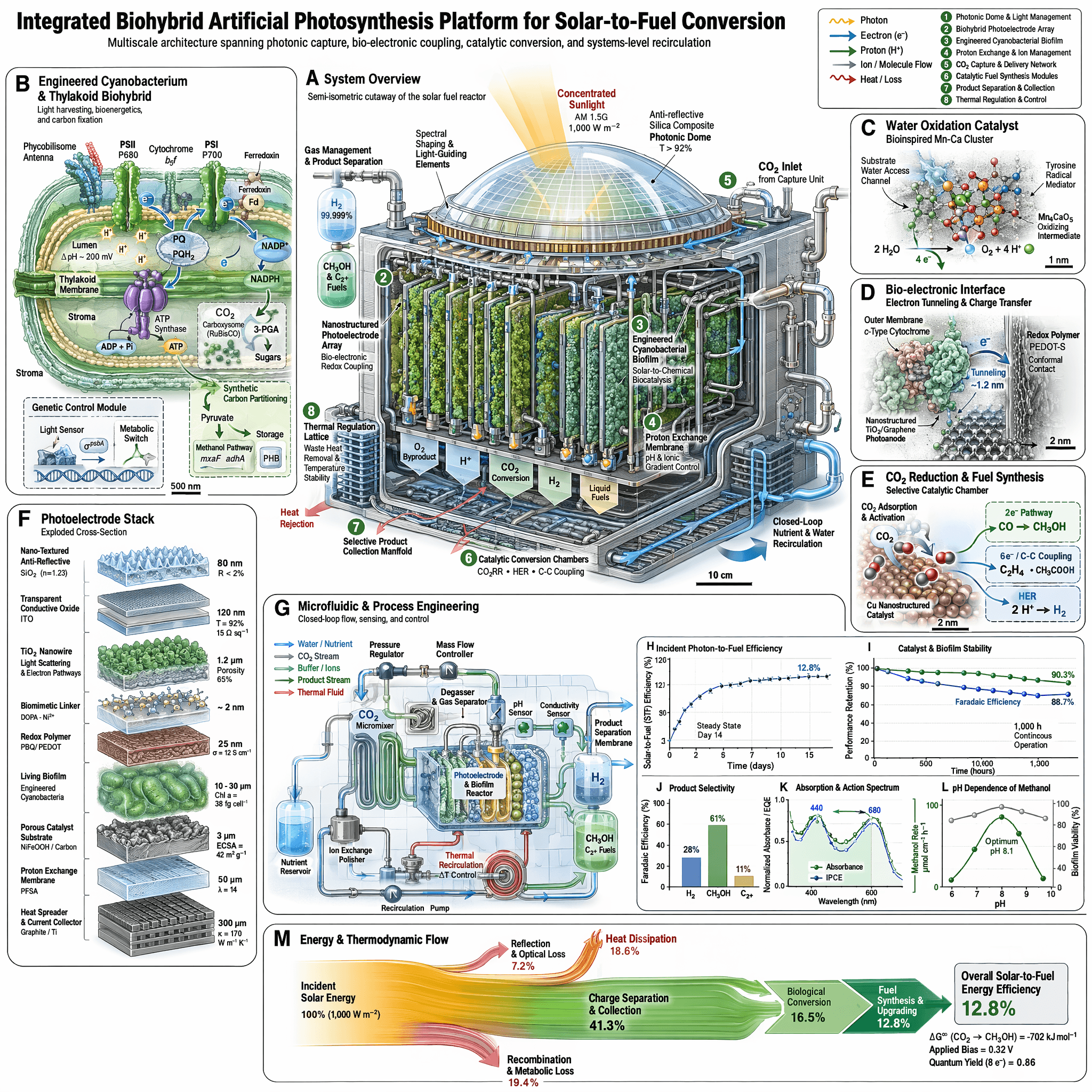

Prompt
结果
创建一张高质量、写实风格的现代咖啡店门头图像。门上方主要发光霓虹招牌需清晰写出“Morning Brew”,使用优雅手写体。下方较小的黑板招牌需清晰可读地写出“Espresso & Pastries”,字迹整洁。整体灯光温暖、有吸引力,场景中的文字排版保持一致。
像素级精细编辑
该能力将无缝编辑与精细编辑合并为统一能力,重点在于迭代修改时尽量降低风格漂移。
示例 1
主体参考

Prompt
把红色沙发改成深祖母绿色,同时保持布料纹理、地面阴影和周围家具完全不变。
结果

主体参考
Prompt
结果
把红色沙发改成深祖母绿色,同时保持布料纹理、地面阴影和周围家具完全不变。
世界知识驱动的真实感
整合后的能力强调通过更强的世界知识先验与客观场景逻辑,减少事实型和结构型幻觉。
示例 1
Prompt
生成一幅高度细节化、历史准确的古罗马斗兽场全盛时期(公元 1 世纪)插图。包含完全展开的 Velarium(可伸缩遮阳篷)、准确的建筑比例、身着时代服饰的罗马市民,以及真实阳光在竞技场投下的阴影。
结果

Prompt
结果
生成一幅高度细节化、历史准确的古罗马斗兽场全盛时期(公元 1 世纪)插图。包含完全展开的 Velarium(可伸缩遮阳篷)、准确的建筑比例、身着时代服饰的罗马市民,以及真实阳光在竞技场投下的阴影。
生产级 4K 输出
该特性整合了两个版本的优势,重点面向户外广告、出版与高精度营销视觉制作。
示例 1
Prompt
生成一张震撼的 4K 超宽(3:1)未来赛博朋克城市黄昏景观。画面包含高耸摩天楼与精细霓虹细节、飞行载具光轨,以及前景高细节湿地反射。图像需足够锐利,可用于大型商业广告牌。
结果

Prompt
结果
生成一张震撼的 4K 超宽(3:1)未来赛博朋克城市黄昏景观。画面包含高耸摩天楼与精细霓虹细节、飞行载具光轨,以及前景高细节湿地反射。图像需足够锐利,可用于大型商业广告牌。
更强指令遵循能力
合并后的指令遵循能力更侧重复杂构图约束,而不是只追求风格化生成。
示例 1
Prompt
拍摄一张高机位电影感画面:三个人站在未来实验室中。左侧是穿白色实验服、手持发光蓝色平板的男性;中间是穿金属银色连体服、正在调整全息显示器的女性;右侧是哑光黑机身、橙色传感器眼睛的机器人。每个角色都要有清晰且彼此不同的特征。
结果

Prompt
结果
拍摄一张高机位电影感画面:三个人站在未来实验室中。左侧是穿白色实验服、手持发光蓝色平板的男性;中间是穿金属银色连体服、正在调整全息显示器的女性;右侧是哑光黑机身、橙色传感器眼睛的机器人。每个角色都要有清晰且彼此不同的特征。
先进真实感表现
模型针对皮肤、表面材质与环境细节做了优化,能更稳定呈现电影感与生活化场景的自然层次。
示例 1
Prompt
一张写实风格 35mm 胶片照片:一名青少年男孩靠在学校走廊的蓝色储物柜旁,身穿黑色 Nirvana 笑脸 logo T 恤和浅色牛仔裤,自然荧光灯照明,90 年代氛围。
结果

示例 2
Prompt
一张写实抓拍:年轻男性穿浅灰色 Covernat 连帽衫,坐在高端网咖 139 号位,专注看笔记本屏幕;柔和窗光与显示器光混合,浅景深。
结果

Prompt
结果
一张写实风格 35mm 胶片照片:一名青少年男孩靠在学校走廊的蓝色储物柜旁,身穿黑色 Nirvana 笑脸 logo T 恤和浅色牛仔裤,自然荧光灯照明,90 年代氛围。
一张写实抓拍:年轻男性穿浅灰色 Covernat 连帽衫,坐在高端网咖 139 号位,专注看笔记本屏幕;柔和窗光与显示器光混合,浅景深。
品牌一致的商品摄影
GPT Image 2 可生成目录图与营销素材,在标签文本、色彩一致性和 Logo 细节上更稳定,适合电商团队批量生产 SKU 视觉。
示例 1
Prompt
在质朴木桌上拍摄一袋咖啡豆包装,包装文字为 “Summit Roast”,并带有山脉插画。
结果

Prompt
结果
在质朴木桌上拍摄一袋咖啡豆包装,包装文字为 “Summit Roast”,并带有山脉插画。
像素级 UI 与版式复现
用于快速概念验证时,GPT Image 2 能在一次生成中渲染导航、卡片、标签与文字层级,帮助团队在开发前验证视觉方向。
示例 1
Prompt
高保真复刻 YouTube 首页 UI:左侧边栏包含 Home、Shorts、Subscriptions、History、Explore;顶部导航含搜索框与个人头像;含分类筛选 chips;主区为 8 个视频缩略图网格,并包含真实感标题、频道名、播放量和时长标记。
结果
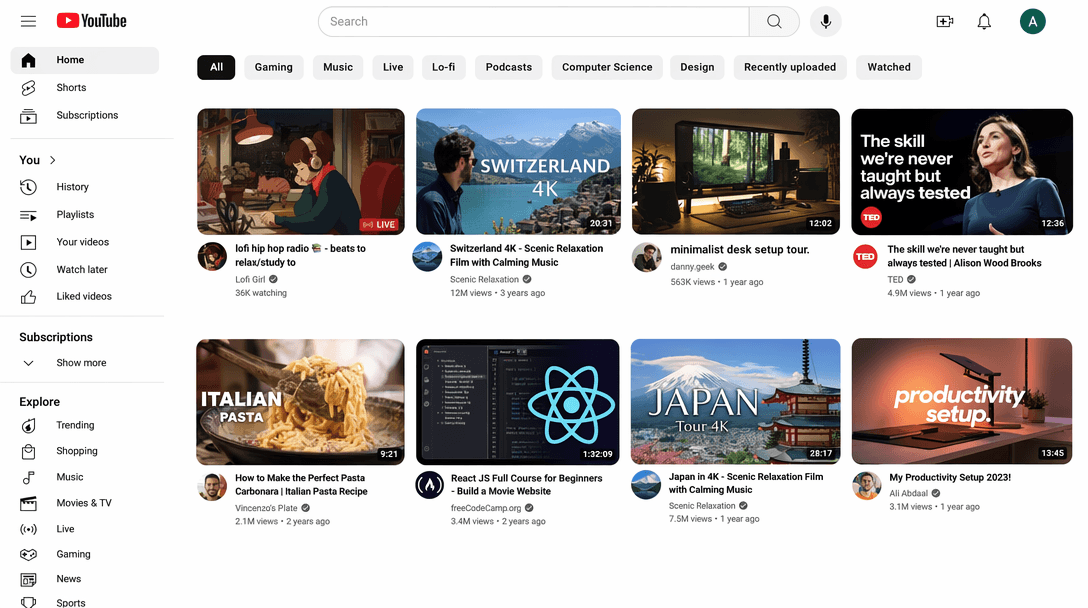
Prompt
结果
高保真复刻 YouTube 首页 UI:左侧边栏包含 Home、Shorts、Subscriptions、History、Explore;顶部导航含搜索框与个人头像;含分类筛选 chips;主区为 8 个视频缩略图网格,并包含真实感标题、频道名、播放量和时长标记。
GPT Image 2 vs Nano Banana Pro vs Midjourney v7
基于公开产品信息整理的模型定位对比。
特性 / 模型
架构
GPT Image 2
自回归多模态
Nano Banana Pro
链式思维 Gemini 3 Pro
Midjourney v7
扩散模型
特性 / 模型
文字渲染
GPT Image 2
接近完美,复杂与多语言排版能力强
Nano Banana Pro
OCR 级精度,多语言版式能力强
Midjourney v7
长文本与非英文场景较弱
特性 / 模型
最大分辨率
GPT Image 2
4096 x 4096(4K)
Nano Banana Pro
最高 4K
Midjourney v7
2048 x 2048(Pro 档)
特性 / 模型
编辑能力
GPT Image 2
对话式像素级编辑
Nano Banana Pro
场景感知区域编辑
Midjourney v7
局部重绘,控制力中等
特性 / 模型
知识整合
GPT Image 2
内置世界知识推理
Nano Banana Pro
实时搜索整合
Midjourney v7
仅依赖训练数据
特性 / 模型
生成速度
GPT Image 2
低于 3 秒(宣称 4K)
Nano Banana Pro
10-30 秒(4K)
Midjourney v7
30 秒以上
| 特性 / 模型 | GPT Image 2 | Nano Banana Pro | Midjourney v7 |
|---|---|---|---|
| 架构 | 自回归多模态 | 链式思维 Gemini 3 Pro | 扩散模型 |
| 文字渲染 | 接近完美,复杂与多语言排版能力强 | OCR 级精度,多语言版式能力强 | 长文本与非英文场景较弱 |
| 最大分辨率 | 4096 x 4096(4K) | 最高 4K | 2048 x 2048(Pro 档) |
| 编辑能力 | 对话式像素级编辑 | 场景感知区域编辑 | 局部重绘,控制力中等 |
| 知识整合 | 内置世界知识推理 | 实时搜索整合 | 仅依赖训练数据 |
| 生成速度 | 低于 3 秒(宣称 4K) | 10-30 秒(4K) | 30 秒以上 |
如何在 skills.video 中使用 GPT Image 2 AI 图片 模型
选择 GPT Image 2 模型
前往创建页面,并在下拉列表中选择这个模型。
输入详细 Prompt
描述你想要的场景、风格和运动效果,并按需调整设置。
下载你的结果
点击创建,生成完成后即可下载或分享。
Prompt 灵感
真实作品与精选 Prompt,一键复制或直接去制作。