GPT Image 2
GPT Image 2 Core Use Cases
Consolidated use-case summary with duplicate audiences merged into broader production workflows.
Marketing & Advertising Professionals
Create ad creatives, social assets, infographic campaigns, and branded email visuals with reliable text rendering and layout consistency.
UI/UX Designers & Product Managers
Rapidly prototype app interfaces, website layouts, and product concepts with controllable hierarchy, typography, and composition.
E-Commerce Product Imaging
Produce product photos and PDP visuals with readable labels, packaging text, barcodes, and brand-consistent styling at scale.
Content Creators & Publishers
Generate visual reports, editorial graphics, covers, and blog media with clear annotation and consistent visual identity.
Education, Research & Technical Communication
Build scientific diagrams, historical reconstructions, and technical illustrations with clearer structure and annotation quality.
Game & Interactive Media Teams
Accelerate concept development for characters, environments, and interface assets during ideation and prototype cycles.
Key Features of GPT Image 2
Production-Ready Text Rendering: Renders dense, multilingual, and typography-heavy layouts with strong punctuation, casing, and placement stability.
Pixel-Level Precision Editing: Applies localized edits while preserving original lighting, material texture, and scene composition.
World-Knowledge Driven Realism: Improves structural plausibility for historical, scientific, and information-dense imagery.
Production-Ready 4K Output: Supports high-resolution output up to 4096 x 4096 and wide-aspect compositions for commercial delivery.
Enhanced Instruction Following: Handles complex multi-subject prompts with tighter control over placement, attributes, and hierarchy.
State-of-the-Art Realism: A quality-first architecture prioritizes photorealistic output with strong lighting and material fidelity.
Brand-Consistent Product Photography: Product labels, logos, and packaging text remain readable and brand-aligned across outputs.
Pixel-Perfect UI And Layout Recreation: Complex interface structures and content-dense layout blocks can be reproduced with high structural fidelity.
Production-Ready Text Rendering
Combining both source sets, this capability targets infographics, signage, UI mockups, and packaging where long strings and small text must remain legible without manual correction.
Example 1
Prompt
Create a high-quality, photorealistic image of a modern coffee shop storefront. The main glowing neon sign above the door should clearly read "Morning Brew" in an elegant cursive font. Below it, a smaller, perfectly legible chalkboard sign should say "Espresso & Pastries" in neat handwriting. The lighting should be cozy and inviting, with consistent typography throughout the scene.
Result

Prompt
Result
Create a high-quality, photorealistic image of a modern coffee shop storefront. The main glowing neon sign above the door should clearly read "Morning Brew" in an elegant cursive font. Below it, a smaller, perfectly legible chalkboard sign should say "Espresso & Pastries" in neat handwriting. The lighting should be cozy and inviting, with consistent typography throughout the scene.
Pixel-Level Precision Editing
This merges the seamless-editing and precision-editing tracks into one core capability focused on minimizing style drift during iterative modifications.
Example 1
Subject Reference

Prompt
Change the color of the red sofa to a deep emerald green, while keeping the texture of the fabric, the shadows cast on the floor, and the surrounding furniture exactly the same.
Result

Subject Reference
Prompt
Result
Change the color of the red sofa to a deep emerald green, while keeping the texture of the fabric, the shadows cast on the floor, and the surrounding furniture exactly the same.
World-Knowledge Driven Realism
The merged version emphasizes reduced hallucinations through stronger world-knowledge priors and better objective scene logic.
Example 1
Prompt
Generate a highly detailed, historically accurate illustration of the Colosseum in Rome during its peak in the 1st century AD. Include the Velarium (the retractable awning) fully deployed, with accurate architectural proportions, Roman citizens in period-appropriate attire, and realistic sunlight casting shadows across the arena.
Result

Prompt
Result
Generate a highly detailed, historically accurate illustration of the Colosseum in Rome during its peak in the 1st century AD. Include the Velarium (the retractable awning) fully deployed, with accurate architectural proportions, Roman citizens in period-appropriate attire, and realistic sunlight casting shadows across the arena.
Production-Ready 4K Output
Consolidated from both versions, this feature targets billboard, publishing, and high-detail marketing production needs.
Example 1
Prompt
Generate a stunning 4K ultra-wide (3:1 aspect ratio) landscape of a futuristic cyberpunk city at dusk. The scene should feature towering skyscrapers with intricate neon details, flying vehicles leaving light trails, and a highly detailed reflective wet street in the foreground. The image must be razor-sharp, suitable for a massive commercial billboard.
Result

Prompt
Result
Generate a stunning 4K ultra-wide (3:1 aspect ratio) landscape of a futuristic cyberpunk city at dusk. The scene should feature towering skyscrapers with intricate neon details, flying vehicles leaving light trails, and a highly detailed reflective wet street in the foreground. The image must be razor-sharp, suitable for a massive commercial billboard.
Enhanced Instruction Following
This merged instruction-following capability focuses on complex composition constraints rather than purely stylistic generation.
Example 1
Prompt
A high-angle cinematic shot of three people standing in a futuristic lab. On the left, a man in a white lab coat holds a glowing blue tablet. In the center, a woman in a metallic silver jumpsuit is adjusting a holographic display. On the right, a robot with a matte black finish and orange sensor eyes is observing. Each character must have distinct features.
Result

Prompt
Result
A high-angle cinematic shot of three people standing in a futuristic lab. On the left, a man in a white lab coat holds a glowing blue tablet. In the center, a woman in a metallic silver jumpsuit is adjusting a holographic display. On the right, a robot with a matte black finish and orange sensor eyes is observing. Each character must have distinct features.
State-of-the-Art Realism
The model is tuned for realistic skin, surfaces, and environmental details. It handles film-like and lifestyle compositions with natural depth and consistent visual coherence in everyday scenes.
Example 1
Prompt
A photorealistic 35mm film photograph of a teenage boy leaning against blue school lockers in a hallway, wearing a black Nirvana t-shirt with the smiley face logo and light wash jeans, natural fluorescent lighting, 1990s aesthetic
Result

Example 2
Prompt
A photorealistic candid shot of a young man in a light grey Covernat hoodie sitting at station 139 in a premium PC cafe, focused on his laptop screen, soft window light mixing with monitor glow, shallow depth of field
Result

Prompt
Result
A photorealistic 35mm film photograph of a teenage boy leaning against blue school lockers in a hallway, wearing a black Nirvana t-shirt with the smiley face logo and light wash jeans, natural fluorescent lighting, 1990s aesthetic
A photorealistic candid shot of a young man in a light grey Covernat hoodie sitting at station 139 in a premium PC cafe, focused on his laptop screen, soft window light mixing with monitor glow, shallow depth of field
Brand-Consistent Product Photography
GPT Image 2 can generate catalog and campaign assets with stable label text, color consistency, and precise logo rendering. It is useful for e-commerce teams producing many SKUs without repeated physical shoots.
Example 1
Prompt
A product photo of a coffee bag labeled 'Summit Roast' with mountain artwork, on a rustic wooden table
Result

Prompt
Result
A product photo of a coffee bag labeled 'Summit Roast' with mountain artwork, on a rustic wooden table
Pixel-Perfect UI And Layout Recreation
For rapid concepting and design exploration, GPT Image 2 can render realistic navigation systems, cards, chips, and typography hierarchy in a single pass, helping teams validate visual direction before implementation.
Example 1
Prompt
A pixel-perfect recreation of the YouTube homepage UI with a left sidebar showing Home, Shorts, Subscriptions, History, and Explore sections, a top navigation bar with search and profile icon, category filter chips, and an 8-video thumbnail grid with realistic titles, channel names, view counts, and duration stamps
Result
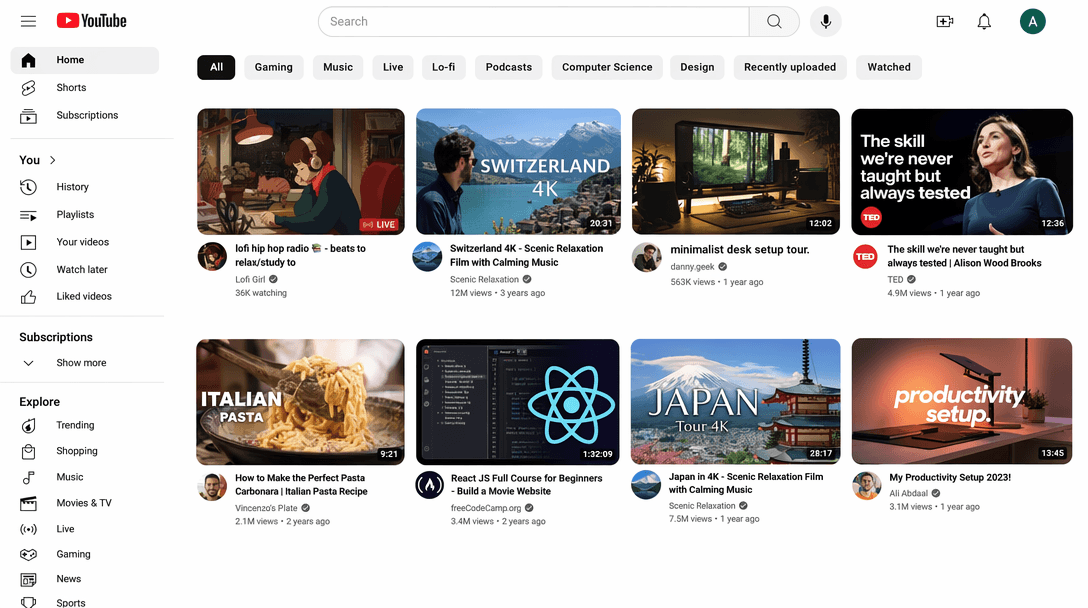
Prompt
Result
A pixel-perfect recreation of the YouTube homepage UI with a left sidebar showing Home, Shorts, Subscriptions, History, and Explore sections, a top navigation bar with search and profile icon, category filter chips, and an 8-video thumbnail grid with realistic titles, channel names, view counts, and duration stamps
GPT Image 2 vs Nano Banana Pro vs Midjourney v7
Model-positioning comparison synthesized from publicly available product pages.
Feature / Model
Architecture
GPT Image 2
Autoregressive multimodal
Nano Banana Pro
Chain-of-thought Gemini 3 Pro
Midjourney v7
Diffusion model
Feature / Model
Text Rendering
GPT Image 2
Near-perfect, complex and multilingual typography
Nano Banana Pro
OCR-level precision, multi-language layout
Midjourney v7
Limited for long strings and non-English text
Feature / Model
Max Resolution
GPT Image 2
4096 x 4096 (4K)
Nano Banana Pro
Up to 4K
Midjourney v7
2048 x 2048 (Pro tier)
Feature / Model
Editing Capabilities
GPT Image 2
Conversational pixel-level editing
Nano Banana Pro
Scene-aware region editing
Midjourney v7
Local inpainting with moderate control
Feature / Model
Knowledge Integration
GPT Image 2
Built-in world-knowledge reasoning
Nano Banana Pro
Real-time search integration
Midjourney v7
Training-data dependent only
Feature / Model
Generation Speed
GPT Image 2
Under 3 seconds (claimed for 4K)
Nano Banana Pro
10-30 seconds (4K)
Midjourney v7
30+ seconds
| Feature / Model | GPT Image 2 | Nano Banana Pro | Midjourney v7 |
|---|---|---|---|
| Architecture | Autoregressive multimodal | Chain-of-thought Gemini 3 Pro | Diffusion model |
| Text Rendering | Near-perfect, complex and multilingual typography | OCR-level precision, multi-language layout | Limited for long strings and non-English text |
| Max Resolution | 4096 x 4096 (4K) | Up to 4K | 2048 x 2048 (Pro tier) |
| Editing Capabilities | Conversational pixel-level editing | Scene-aware region editing | Local inpainting with moderate control |
| Knowledge Integration | Built-in world-knowledge reasoning | Real-time search integration | Training-data dependent only |
| Generation Speed | Under 3 seconds (claimed for 4K) | 10-30 seconds (4K) | 30+ seconds |
How To Use GPT Image 2 AI Image Model on skills.video
Select the GPT Image 2 model
Head to the create page and choose this model from the dropdown list.
Input your detailed prompt
Describe the scene, style, and motion you want. Adjust settings as needed.
Download your result
Click create, then download or share once the generation finishes.
Prompt Gallery
Real community works and curated prompts — copy or reuse with one click.